
4. pix2pix#
![]()
在上一章中,我们使用GAN模型将黑白图像转换为彩色图像。
在本章中,我们将使用基于 cGAN(条件生成对抗网络)的pix2pix pix2pix 模型和由 19 世纪插图组成的Victorian400 Victorian400数据集来学习和对模型进行颜色测试。
4.1 数据集下载#
首先,让我们下载 Victorian400 数据集。我们将使用 Fake Research Institute 制作的工具下载并解压数据集。
!git clone https://github.com/Pseudo-Lab/Tutorial-Book-Utils
!python Tutorial-Book-Utils/PL_data_loader.py --data GAN-Colorization
!unzip -q Victorian400-GAN-colorization-data.zip
'git' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
python: can't open file 'D:\3000-code\deeplearning\DeepLearning2023\Deeplearning\chapters\chpt3\Tutorial-Book-Utils\PL_data_loader.py': [Errno 2] No such file or directory
'unzip' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
导入基本模块
import os
import glob
import numpy as np
import datetime
import matplotlib.pyplot as plt
from PIL import Image
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
from torchvision.utils import save_image
import torch.nn as nn
import torch.nn.functional as F
import torch
import torchvision
from torch.autograd import Variable
4.2 数据集类定义#
VictorianDataset该类指定一个按文件名顺序一起加载黑白照片(灰色)和彩色照片(调整大小)的函数__init__、一个将每个图像文件保存为像素的函数__getitem__以及一个返回文件数量的函数。len
class VictorianDataset(Dataset):
def __init__(self, root, color_transforms_=None, gray_transforms_=None):
"""
初始化数据集。
参数:
root (str): 数据集的根目录。
color_transforms_ (callable, optional): 彩色图像的转换函数。默认为 None。
gray_transforms_ (callable, optional): 灰度图像的转换函数。默认为 None。
"""
# 将传入的颜色变换列表组合成一个变换函数
self.color_transforms = transforms.Compose(color_transforms_)
# 将传入的灰度变换列表组合成一个变换函数
self.gray_transforms = transforms.Compose(gray_transforms_)
# 对根目录下的灰度图像文件进行排序
self.gray_files = sorted(glob.glob(os.path.join(root, 'gray') + "/*.*"))
# 对根目录下的彩色图像文件进行排序
self.color_files = sorted(glob.glob(os.path.join(root, 'resized') + "/*.*"))
def __getitem__(self, index):
"""
获取数据集中的一个样本。
参数:
index (int): 样本的索引。
返回:
dict: 包含灰度图像和彩色图像的字典。
"""
# 打开灰度图像文件并转换为RGB模式
gray_img = Image.open(self.gray_files[index % len(self.gray_files)]).convert("RGB")
# 打开彩色图像文件并转换为RGB模式
color_img = Image.open(self.color_files[index % len(self.color_files)]).convert("RGB")
# 对灰度图像应用变换
gray_img = self.gray_transforms(gray_img)
# 对彩色图像应用变换
color_img = self.color_transforms(color_img)
# 返回包含灰度图像和彩色图像的字典
return {"A": gray_img, "B": color_img}
def __len__(self):
"""
返回数据集中的样本数量。
返回:
int: 数据集的长度。
"""
# 返回灰度图像文件的数量
return len(self.gray_files)
提前指定批量大小和图像大小。root指定文件夹位置。对于图像大小,将高度和宽度均设置为 256。 pix2pix 模型使用 256 x 256 的图像尺寸。 (补充一下)
root = ''
batch_size = 12
img_height = 256
img_width = 256
transform.NormalizeNormalize指定尺寸。我们将使用第 2.4 节中获得的平均值和标准差进行标准化。
color_mean = [0.58090717, 0.52688643, 0.45678478]
color_std = [0.25644188, 0.25482641, 0.24456465]
gray_mean = [0.5350533, 0.5350533, 0.5350533]
gray_std = [0.25051587, 0.25051587, 0.25051587]
color_transforms_ = [
transforms.ToTensor(),
transforms.Normalize(mean=color_mean, std=color_std),
]
gray_transforms_ = [
transforms.ToTensor(),
transforms.Normalize(mean=gray_mean, std=gray_std),
]
train_loader = DataLoader(
VictorianDataset(root, color_transforms_=color_transforms_, gray_transforms_=gray_transforms_),
batch_size=batch_size,
shuffle=True
)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[6], line 1
----> 1 train_loader = DataLoader(
2 VictorianDataset(root, color_transforms_=color_transforms_, gray_transforms_=gray_transforms_),
3 batch_size=batch_size,
4 shuffle=True
5 )
File D:\Program Files\Python39\lib\site-packages\torch\utils\data\dataloader.py:376, in DataLoader.__init__(self, dataset, batch_size, shuffle, sampler, batch_sampler, num_workers, collate_fn, pin_memory, drop_last, timeout, worker_init_fn, multiprocessing_context, generator, prefetch_factor, persistent_workers, pin_memory_device)
374 else: # map-style
375 if shuffle:
--> 376 sampler = RandomSampler(dataset, generator=generator) # type: ignore[arg-type]
377 else:
378 sampler = SequentialSampler(dataset) # type: ignore[arg-type]
File D:\Program Files\Python39\lib\site-packages\torch\utils\data\sampler.py:164, in RandomSampler.__init__(self, data_source, replacement, num_samples, generator)
159 raise TypeError(
160 f"replacement should be a boolean value, but got replacement={self.replacement}"
161 )
163 if not isinstance(self.num_samples, int) or self.num_samples <= 0:
--> 164 raise ValueError(
165 f"num_samples should be a positive integer value, but got num_samples={self.num_samples}"
166 )
ValueError: num_samples should be a positive integer value, but got num_samples=0
def reNormalize(img, mean, std):
img = img.numpy().transpose(1, 2, 0)
img = img * std + mean
img = img.clip(0, 1)
return img
现在,让我们可视化加载的数据是否已正确保存为像素。
fig = plt.figure(figsize=(10, 5))
rows = 1
cols = 2
for X in train_loader :
print(X['A'].shape, X['B'].shape)
ax1 = fig.add_subplot(rows, cols, 1)
ax1.imshow(reNormalize(X["A"][0], gray_mean, gray_std))
ax1.set_title('gray img')
ax2 = fig.add_subplot(rows, cols, 2)
ax2.imshow(reNormalize(X["B"][0], color_mean, color_std))
ax2.set_title('color img')
plt.show()
break
torch.Size([12, 3, 256, 256]) torch.Size([12, 3, 256, 256])

4.3 模型构建#
现在让我们设计 pix2pix 模型。 pix2pix的特点是它使用U-NET而不是典型的编码器-解码器。 U-NET 的一个特点是,与典型的编码器-解码器不同,它具有跳跃连接,可以更好地定位编码器层和解码器层之间的连接。例如,如果第一个编码器层大小为 256 x 256 x 3,则最后一个解码器层大小也将为 256 x 256 x 3。 U-NET的特点是它结合了相同大小的编码器-解码器层,从而实现更有效和更快的性能。
现在让我们设计一个带有内置跳跃连接的 U-NET 生成器。如前一章所述,GAN 模型具有 U-NET 生成器,并通过跳跃连接提供编码器-解码器层之间的本地化。
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
# U-NET 생성
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
super(UNetDown, self).__init__()
layers = [nn.Conv2d(in_size, out_size, 4, 2, 1, bias=False)]
if normalize:
layers.append(nn.InstanceNorm2d(out_size))
layers.append(nn.LeakyReLU(0.2))
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
def __init__(self, in_size, out_size, dropout=0.0):
super(UNetUp, self).__init__()
layers = [
nn.ConvTranspose2d(in_size, out_size, 4, 2, 1, bias=False),
nn.InstanceNorm2d(out_size),
nn.ReLU(inplace=True),
]
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x, skip_input):
x = self.model(x)
x = torch.cat((x, skip_input), 1)
return x
class GeneratorUNet(nn.Module):
def __init__(self, in_channels=3, out_channels=3):
super(GeneratorUNet, self).__init__()
self.down1 = UNetDown(in_channels, 64, normalize=False)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128, 256)
self.down4 = UNetDown(256, 512, dropout=0.5)
self.down5 = UNetDown(512, 512, dropout=0.5)
self.down6 = UNetDown(512, 512, dropout=0.5)
self.down7 = UNetDown(512, 512, dropout=0.5)
self.down8 = UNetDown(512, 512, normalize=False, dropout=0.5)
self.up1 = UNetUp(512, 512, dropout=0.5)
self.up2 = UNetUp(1024, 512, dropout=0.5)
self.up3 = UNetUp(1024, 512, dropout=0.5)
self.up4 = UNetUp(1024, 512, dropout=0.5)
self.up5 = UNetUp(1024, 256)
self.up6 = UNetUp(512, 128)
self.up7 = UNetUp(256, 64)
self.final = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(128, out_channels, 4, padding=1),
nn.Tanh(),
)
def forward(self, x):
# U-Net generator with skip connections from encoder to decoder
d1 = self.down1(x)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
d7 = self.down7(d6)
d8 = self.down8(d7)
u1 = self.up1(d8, d7)
u2 = self.up2(u1, d6)
u3 = self.up3(u2, d5)
u4 = self.up4(u3, d4)
u5 = self.up5(u4, d3)
u6 = self.up6(u5, d2)
u7 = self.up7(u6, d1)
return self.final(u7)
现在让我们创建一个鉴别器。
class Discriminator(nn.Module):
def __init__(self, in_channels=3):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalization=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalization:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(in_channels * 2, 64, normalization=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1, bias=False)
)
def forward(self, img_A, img_B):
# Concatenate image and condition image by channels to produce input
img_input = torch.cat((img_A, img_B), 1)
return self.model(img_input)
现在让我们看看生成器和判别器的结构。
GeneratorUNet().apply(weights_init_normal)
GeneratorUNet(
(down1): UNetDown(
(model): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2)
)
)
(down2): UNetDown(
(model): Sequential(
(0): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): LeakyReLU(negative_slope=0.2)
)
)
(down3): UNetDown(
(model): Sequential(
(0): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): LeakyReLU(negative_slope=0.2)
)
)
(down4): UNetDown(
(model): Sequential(
(0): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(512, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): LeakyReLU(negative_slope=0.2)
(3): Dropout(p=0.5, inplace=False)
)
)
(down5): UNetDown(
(model): Sequential(
(0): Conv2d(512, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(512, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): LeakyReLU(negative_slope=0.2)
(3): Dropout(p=0.5, inplace=False)
)
)
(down6): UNetDown(
(model): Sequential(
(0): Conv2d(512, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(512, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): LeakyReLU(negative_slope=0.2)
(3): Dropout(p=0.5, inplace=False)
)
)
(down7): UNetDown(
(model): Sequential(
(0): Conv2d(512, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(512, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): LeakyReLU(negative_slope=0.2)
(3): Dropout(p=0.5, inplace=False)
)
)
(down8): UNetDown(
(model): Sequential(
(0): Conv2d(512, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2)
(2): Dropout(p=0.5, inplace=False)
)
)
(up1): UNetUp(
(model): Sequential(
(0): ConvTranspose2d(512, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(512, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
)
)
(up2): UNetUp(
(model): Sequential(
(0): ConvTranspose2d(1024, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(512, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
)
)
(up3): UNetUp(
(model): Sequential(
(0): ConvTranspose2d(1024, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(512, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
)
)
(up4): UNetUp(
(model): Sequential(
(0): ConvTranspose2d(1024, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(512, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
)
)
(up5): UNetUp(
(model): Sequential(
(0): ConvTranspose2d(1024, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): ReLU(inplace=True)
)
)
(up6): UNetUp(
(model): Sequential(
(0): ConvTranspose2d(512, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): ReLU(inplace=True)
)
)
(up7): UNetUp(
(model): Sequential(
(0): ConvTranspose2d(256, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): InstanceNorm2d(64, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): ReLU(inplace=True)
)
)
(final): Sequential(
(0): Upsample(scale_factor=2.0, mode=nearest)
(1): ZeroPad2d(padding=(1, 0, 1, 0), value=0.0)
(2): Conv2d(128, 3, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1))
(3): Tanh()
)
)
Discriminator().apply(weights_init_normal)
Discriminator(
(model): Sequential(
(0): Conv2d(6, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(3): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(9): InstanceNorm2d(512, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): ZeroPad2d(padding=(1, 0, 1, 0), value=0.0)
(12): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1), bias=False)
)
)
如果你看一下图 4-1,它直观地展示了生成器和判别器的工作原理,生成器生成的图像与输入图像配对作为输出,判别器确定它们的相似程度。另外,输入图像和目标图像同时输入并由鉴别器进行比较。比较这两对的结果值是鉴别器权重,通过这个过程更新。
当鉴别器值更新时,生成器权重也会通过以下过程更新以创建新图像。模型学习不断重复这个过程。


图4-1 生成器和判别器工作原理可视化(来源:https ://neurohive.io/en/popular-networks/pix2pix-image-to-image-translation/ )
现在让我们指定参数并学习pix2pix模型。这里n_epoch是要学习的总时期数,lr是学习损失。checkpoint_interval是训练期间存储模型权重的时间间隔。
n_epochs = 100
dataset_name = "Victorian400"
lr = 0.0002
b1 = 0.5 # adam: decay of first order momentum of gradient
b2 = 0.999 # adam: decay of first order momentum of gradient
decay_epoch = 100 # epoch from which to start lr decay
#n_cpu = 8 # number of cpu threads to use during batch generation
channels = 3 # number of image channels
checkpoint_interval = 20 # interval between model checkpoints
os.makedirs("images/%s/val" % dataset_name, exist_ok=True)
os.makedirs("images/%s/test" % dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % dataset_name, exist_ok=True)
# Loss functions
criterion_GAN = torch.nn.MSELoss()
criterion_pixelwise = torch.nn.L1Loss()
# Loss weight of L1 pixel-wise loss between translated image and real image
lambda_pixel = 100
# Calculate output of image discriminator (PatchGAN)
patch = (1, img_height // 2 ** 4, img_width // 2 ** 4)
# Initialize generator and discriminator
generator = GeneratorUNet()
discriminator = Discriminator()
cuda = True if torch.cuda.is_available() else False
if cuda:
generator = generator.cuda()
discriminator = discriminator.cuda()
criterion_GAN.cuda()
criterion_pixelwise.cuda()
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2))
# Tensor type
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
sample_images看函数定义有,,,gray我定义为黑白照片,彩色照片,黑白转彩色的照片。是通过比较而学习的,并在此基础上创建的。coloroutputgraycoloroutputgraycoloroutput
def sample_images(epoch, loader, mode):
imgs = next(iter(loader))
gray = Variable(imgs["A"].type(Tensor))
color = Variable(imgs["B"].type(Tensor))
output = generator(gray)
gray_img = torchvision.utils.make_grid(gray.data, nrow=6)
color_img = torchvision.utils.make_grid(color.data, nrow=6)
output_img = torchvision.utils.make_grid(output.data, nrow=6)
rows = 3
cols = 1
ax1 = fig.add_subplot(rows, cols, 1)
ax1.imshow(reNormalize(gray_img.cpu(), gray_mean, gray_std))
ax1.set_title('gray')
ax2 = fig.add_subplot(rows, cols, 2)
ax2.imshow(reNormalize(color_img.cpu(), color_mean, color_std))
ax2.set_title('color')
ax3 = fig.add_subplot(rows, cols, 3)
ax3.imshow(reNormalize(output_img.cpu(), color_mean, color_std))
ax3.set_title('output')
plt.show()
fig.savefig("images/%s/%s/epoch_%s.png" % (dataset_name, mode, epoch), pad_inches=0)
4.4 模型训练¶#
现在epoch让我们开始学习您指定的内容。
# ----------
# Training
# ----------
for epoch in range(1, n_epochs+1):
start_time = datetime.datetime.now()
for i, batch in enumerate(train_loader):
# Model inputs
gray = Variable(batch["A"].type(Tensor))
color = Variable(batch["B"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((gray.size(0), *patch))), requires_grad=False)
fake = Variable(Tensor(np.zeros((gray.size(0), *patch))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad()
# GAN loss
output = generator(gray)
pred_fake = discriminator(output, gray)
loss_GAN = criterion_GAN(pred_fake, valid)
# Pixel-wise loss
loss_pixel = criterion_pixelwise(output, color)
# Total loss
loss_G = loss_GAN + lambda_pixel * loss_pixel
loss_G.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Real loss
pred_real = discriminator(color, gray)
loss_real = criterion_GAN(pred_real, valid)
# Fake loss
pred_fake = discriminator(output.detach(), gray)
loss_fake = criterion_GAN(pred_fake, fake)
# Total loss
loss_D = 0.5 * (loss_real + loss_fake)
loss_D.backward()
optimizer_D.step()
epoch_time = datetime.datetime.now() - start_time
if (epoch) % checkpoint_interval == 0:
fig = plt.figure(figsize=(18, 18))
sample_images(epoch, train_loader, 'val')
torch.save(generator.state_dict(), "saved_models/%s/generator_%d.pth" % (dataset_name, epoch))
torch.save(discriminator.state_dict(), "saved_models/%s/discriminator_%d.pth" % (dataset_name, epoch))
print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, pixel: %f, adv: %f] ETA: %s" % (epoch,
n_epochs,
i+1,
len(train_loader),
loss_D.item(),
loss_G.item(),
loss_pixel.item(),
loss_GAN.item(),
epoch_time))

[Epoch 20/100] [Batch 34/34] [D loss: 0.003363] [G loss: 36.174591, pixel: 0.351734, adv: 1.001226] ETA: 0:00:15.931600

[Epoch 40/100] [Batch 34/34] [D loss: 0.010069] [G loss: 22.281427, pixel: 0.212988, adv: 0.982629] ETA: 0:00:15.914369

[Epoch 60/100] [Batch 34/34] [D loss: 0.001813] [G loss: 29.513786, pixel: 0.284740, adv: 1.039806] ETA: 0:00:15.915187

[Epoch 80/100] [Batch 34/34] [D loss: 0.001550] [G loss: 18.294107, pixel: 0.172993, adv: 0.994772] ETA: 0:00:15.893250

[Epoch 100/100] [Batch 34/34] [D loss: 0.399534] [G loss: 22.823000, pixel: 0.224467, adv: 0.376251] ETA: 0:00:15.921102
如果您查看上面的示例照片,它们是按从上到下的顺序排列的黑白 - 目标 - 输出图像。您可以清楚地看到,随着 epoch 数量的增加,学习效果正在发生。通过检查采样图像,您可以找到合适的批量大小和时期数。
4.5 预测和性能评估#
现在,让我们使用学习到的模型对第 6 章中的测试集进行实验。
test_root = root + 'test/'
test_batch_size = 6
test_loader = DataLoader(
VictorianDataset(test_root, color_transforms_=color_transforms_, gray_transforms_=gray_transforms_),
batch_size=test_batch_size,
shuffle=False
)
我们来看看测试集图像文件是否正常输出。
fig = plt.figure(figsize=(10, 5))
rows = 1
cols = 2
for X in test_loader:
print(X['A'].shape, X['B'].shape)
ax1 = fig.add_subplot(rows, cols, 1)
ax1.imshow(reNormalize(X["A"][0], gray_mean, gray_std))
ax1.set_title('gray img')
ax2 = fig.add_subplot(rows, cols, 2)
ax2.imshow(reNormalize(X["B"][0], color_mean, color_std))
ax2.set_title('color img')
plt.show()
break
torch.Size([6, 3, 256, 256]) torch.Size([6, 3, 256, 256])
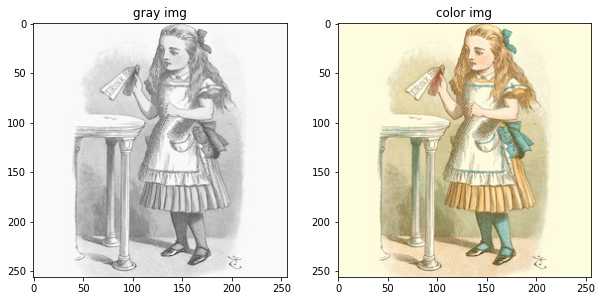
现在让我们加载学习的模型并预测测试集图像文件。下面的代码应用具有最大历元数的训练模型。如果指定所需的 epoch 数n_epochs,则可以加载该 epoch 数的学习模型。
generator.load_state_dict(torch.load("saved_models/%s/generator_%d.pth" % (dataset_name, n_epochs)))
discriminator.load_state_dict(torch.load("saved_models/%s/discriminator_%d.pth" % (dataset_name, n_epochs)))
<All keys matched successfully>
generator.eval()
discriminator.eval()
fig = plt.figure(figsize=(18,10))
sample_images(n_epochs, test_loader, 'test')

这些是按从上到下的顺序排列的黑白目标输出测试图像。您可能会发现某些照片的打印效果比原始照片更好。经证实,在生成器中添加了 U-NET 的 cGAN 模型在预测颜色方面比 GAN 模型产生了更好的结果。
如果模型结构设计得很好可以满足特定目标,那么即使使用如此小的数据集也可以产生良好的结果。当然,如果添加大量高质量数据,可以获得改进的结果。现在,根据学习到的模型为黑白图片着色怎么样?