
1. NLP模型简介 (Introduction to NLP Model)(未完待续)#
![]()
语言模型(Language Model)是一种为句子或单词分配概率,以便计算机能够进行处理的模型。更进一步来说,语言建模(Language Modeling)是指基于现有的数据集,在给定任务范围内对单词或句子进行预测的工作。在自然语言处理(Natural Language Processing)中,自然语言顾名思义就是人类所使用的语言,其他种类的语言包括计算机语言(Computer Language)、手语(Sign Language)、肢体语言(Body Language)等。将计算机处理自然语言的过程加上 “处理”(Processing)这一表述,就称之为自然语言处理(Natural Language Processing)。 为了进行自然语言处理,预处理(preprocessing)是必不可少的,之后我们将通过多种语言模型来试着进行问题生成工作。在本教程中,我们将介绍的不是传统上使用的基于统计的语言模型,而是近来经常使用的基于深度学习的自然语言处理模型。 迁移学习(Transfer Learning)在自然语言处理领域带来了惊人的发展。像谷歌的 BERT、OpenAI 的 GPT 这类迁移学习模型,以性能优异而闻名。此后,XLNet、RoBERTa、T5 等也在不断被开发,以便迁移学习能够应用于多种方式。在本教程中,我们希望通过基于迁移学习的模型 T5、BERT、GPT-2 来执行问题生成工作。
1.1 问题生成任务 (Question Generation Task)#
关于问题生成工作的分类因学者不同而有多种划分方式。首先,在本章中,我们将基于库尔迪等人(Kurdi et al.)的《面向教育目的的自动问题生成的系统综述》(“A Systematic Review of Automatic Question Generation for Educational Purposes”)这项研究来进行说明。在问题生成过程中,大致存在理解阶段和生成过程这两个阶段。将接收作为输入数据的句子,计算机对其进行理解的过程视为理解环节。经过这样的理解过程后,以输入数据为基础进行问题生成的过程被称为生成过程。
在理解阶段,存在基于句法学(syntax-based)和基于语义学(semantic-based)的方法。
基于句法学的方法是通过输入诸如文本的句法树(syntax tree)这样的输入内容来生成问题。例如,基于句法学的模型会不考虑句子内单词的含义,而是通过词性(Part of Speech)标注,提取句子内的句法特征,把握词性之间的关系,进而决定问题的生成。
基于语义学的方法是通过把握句子中的语义关系来生成问题。它超越了句法层面的方法,有必要对输入数据进行更深入的理解,不仅仅是提取词性的含义,还必须能够推断词性之间的含义。例如,“bank”这个词的意思可能是“银行”,也可能是“堤岸”。这是由其在段落中与相关单词的关系来确定具体含义的。
在生成过程中,存在模板(template)、规则(rule)以及统计方法(statistical methods)。
在基于模板(template-based)的情况下,先确定问题结构的模板,然后通过文本的语义或句法学方法来提取特征,进而生成问题。规则方法是利用句子中词性的注释(annotations)信息来生成问题。例如,如果是要生成诸如“where”“which”“when”这类以“wh”开头的疑问词问题的工作,就会接收在相应位置带有“wh”的词性注释信息,进而生成以“wh”开头的疑问词问题。最后,统计方法的典型代表是序列到序列(sequence-to-sequence)方法。通过对数据集进行学习,利用句子中某个单词出现的概率来生成问题。但是,如果在学习过的语料库中没有相应的单词序列,就会出现概率为0或者未定义的情况,从而无法准确预测单词,这一问题被称为稀疏问题(the Sparsity Problem)。为了解决这个问题,虽然会使用诸如n-gram这样的方法,但仍然无法突破统计方法的局限性。
接下来,让我们简要了解一下将用于问题生成工作的T5、BERT、GPT模型。
1.2 T5#
T5 模型以“Text-to-Text Transfer Transformer”中出现 5 次的首字母 T 命名。 T5 模型是在“Colossal Clean Crawled Corpus”(C4)数据集上进行预训练的。 C4数据集是文本数据,是一个文本没有标注的大数据集,是为了学习T5模型而创建的数据集。

图1-1 T5模型工作原理可视化(来源:https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html)
T5 模型在 C4 数据集上进行了预训练,旨在适应各种下游任务。例如,如图 1-1 所示,现在使用 T5 模型可以轻松实现机器翻译、问答和文本摘要等任务。与 BERT 只能在输入范围内输出不同,T5 模型的优势在于可以以文本到文本的格式输入和输出。
1.3 BERT#
BERT (Bidirectional Encoder Representations from Transformers)它是 2019 年 10 月 25 日由谷歌研究团队公开的自然语言处理预训练模型。BERT 模型支持超过 100 种语言的学习,有 “BERT-Base”“BERT-Large”“BERT-Base, Multilingual” 以及 “BERT-Base, Chinese” 等模型。在各个模型后面会加上 “Cased” 和 “Uncased”,其中 “Uncased” 这种情况对应的是不区分大小写的模型。 可以利用 BERT 来执行特定任务,为此,需要进行微调(fine-tuning)工作以执行具体任务。BERT 作为预训练的语言模型,通过微调能够执行期望的工作。利用预训练的语言模型来执行下游任务(down-stream tasks)的方法有 “基于特征”(feature-based)和微调(fine-tuning)这两种方式。“基于特征” 的方法包含像 Word2Vec、GloVe、ELMo 这样的方式,而微调(fine-tuning)方式的典型代表是 GPT 模型。 在 BERT 发布之时,人们经常将它与 GPT-2 进行比较,这两个模型都使用微调(fine-tuning)方式,不过 GPT-2 是单向(unidirectional)语言模型,而 BERT 是双向(bidirectional)语言模型,这就是二者的差异所在。在之后,开发了 GPT 的 OpenAI 推出了像 BERT 一样的双向语言模型 GPT-3。 双向语言模型的优点在于,像 “填空”(fill-in-the-blanks)这类需要依据前后语境来推测空白处合适单词的工作中,它展现出了非常高的性能。
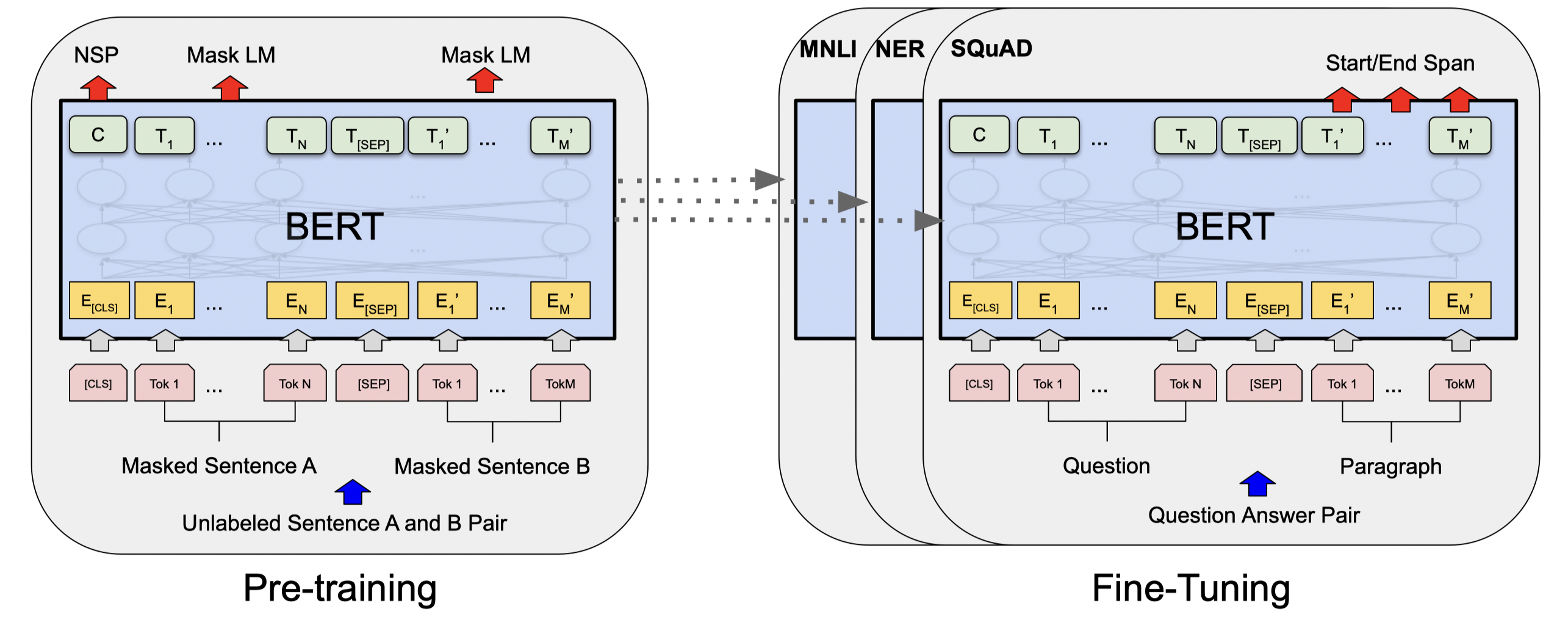
图1-2 BERT模型预学习和微调可视化 (Devlin et al.)
BERT模型经历两个过程:先验学习( pre-training)和微调( )。fine-tuning在预学习过程中,使用未标记的数据通过预学习任务来学习模型。在后续的微调过程中,BERT模型从预先训练的参数开始,利用标记数据进行微调。
通过微调 BERT 模型,您可以执行各种任务,例如单词预测、问题生成和情感分析。在本教程中,我们将使用它来执行问题生成任务。
1.4 GPT#
GPT模型是由Elon Musk和Sam Altman创立的openAI开发的自然语言处理模型。 GPT-1、GPT-2、GPT-3依次发布,继2019年GPT-2发布后,其令人难以置信的性能让很多人感到惊讶,2020年6月,GPT-3再次引入全球。给人工智能界带来了一场风暴。
然而,GPT 模型并不完美。 GPT-2 是一种单向语言模型,经过训练可以预测输入提示后的单词。有人指出,这与双向语言模型 BERT 相比具有明显的缺点。然而,2019 年,有工作展示了 GPT-2(一种单向语言模型)在文本生成方面的真正价值。在使用人工智能的文本生成任务中,单向模型比双向模型表现出更好的性能。 GPT-1有1.17亿个参数,GPT-2有15.42亿个参数,大约是GPT-1的12.8倍,大约800万个文档,40GB的数据,这是一个学习了三个的模型。

图1-3 BERT、T5、GPT-3模型训练时间 (Brown, et al.)
2020 年 6 月宣布的 GPT-3 代表了一次巨大的飞跃。 GPT-3 拥有 1750 亿个参数,大约是 GPT-2 的 12 倍,是在过滤前 45TB、过滤后 570GB 的海量数据集上训练的模型。如图1-3所示,可以推断GPT-3训练时间足够大,足以超过BERT和T5模型。
1.5 结论#
在本章中,我们简要介绍了 T5、BERT 和 GPT 模型,它们都是基于迁移学习的模型。在下一章中,我们将查看教程中使用的数据集,在第 3 章和第 4 章中,我们将使用 T5、BERT 和 GPT 模型执行问题创建任务。
1.6 相关文献#
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Kurdi, G., Leo, J., Parsia, B., Sattler, U., & Al-Emari, S. (2020). A systematic review of automatic question generation for educational purposes. International Journal of Artificial Intelligence in Education, 30(1), 121-204.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2019). Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683.
Roberts, A., & Raffel, C. (2020). Exploring Transfer Learning with T5: The Text-To-Text Transfer Transformer. (https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html)