
4. LSTM#
![]()
在第3章中,我们练习了将约翰·霍普金斯大学提供的时间序列数据转换为监督学习数据的过程。在本章中,我们将使用 LSTM 构建模型来预测韩国未来的冠状病毒确诊病例数。
在4.1和4.2节中,我们将检索韩国累计确诊的冠状病毒病例数,并将数据分为训练数据、验证数据和测试数据。在 4.3 节中,我们将定义 LSTM 模型,在 4.4 节中,我们将训练定义的模型。最后,让我们检查一下冠状病毒确诊病例数的预测值。
首先,导入基本模块。
import torch
import os
import numpy as np
import pandas as pd
from tqdm import tqdm
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
from sklearn.preprocessing import MinMaxScaler
from pandas.plotting import register_matplotlib_converters
from torch import nn, optim
%matplotlib inline
%config InlineBackend.figure_format='retina'
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
rcParams['figure.figsize'] = 14, 10
register_matplotlib_converters()
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
<torch._C.Generator at 0x2d4990901f0>
4.1 数据下载#
为了进行建模实践,我们将导入韩国累计确诊的冠状病毒数据。我们将使用 2.1 节中的代码。
!git clone https://github.com/Pseudo-Lab/Tutorial-Book-Utils
!python Tutorial-Book-Utils/PL_data_loader.py --data COVIDTimeSeries
!unzip -q COVIDTimeSeries.zip
'git' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
python: can't open file 'D:\3000-code\deeplearning\DeepLearning2023\Deeplearning\chapters\chpt4\Tutorial-Book-Utils\PL_data_loader.py': [Errno 2] No such file or directory
'unzip' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
4.2 数据预处理¶#
使用第 3 章中练习的代码,我们将把时间序列数据转换为监督学习数据,然后将其分为学习数据、验证数据和测试数据。然后,我们将使用训练数据的统计数据进行缩放。
# 读取全球COVID-19确诊数据
confirmed = pd.read_csv('time_series_covid19_confirmed_global.csv')
# 筛选出韩国的数据
confirmed[confirmed['Country/Region']=='Korea, South']
# 提取韩国数据中从第4列开始的所有列,并转置
korea = confirmed[confirmed['Country/Region']=='Korea, South'].iloc[:,4:].T
# 将索引转换为日期格式
korea.index = pd.to_datetime(korea.index)
# 计算每日新增确诊病例数
daily_cases = korea.diff().fillna(korea.iloc[0]).astype('int')
# 定义一个函数,用于创建时间序列数据
def create_sequences(data, seq_length):
xs = []
ys = []
for i in range(len(data)-seq_length):
# 取长度为seq_length的时间序列作为输入特征
x = data.iloc[i:(i+seq_length)]
# 取时间序列的下一个值作为目标值
y = data.iloc[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
# 将每日新增确诊病例数转换为时间序列数据
seq_length = 5
X, y = create_sequences(daily_cases, seq_length)
# 划分训练集、验证集和测试集
train_size = int(327 * 0.8)
X_train, y_train = X[:train_size], y[:train_size]
X_val, y_val = X[train_size:train_size+33], y[train_size:train_size+33]
X_test, y_test = X[train_size+33:], y[train_size+33:]
# 计算训练集的最小值和最大值
MIN = X_train.min()
MAX = X_train.max()
# 定义一个函数,用于对数据进行最小-最大归一化
def MinMaxScale(array, min, max):
return (array - min) / (max - min)
# 对训练集、验证集和测试集进行归一化
X_train = MinMaxScale(X_train, MIN, MAX)
y_train = MinMaxScale(y_train, MIN, MAX)
X_val = MinMaxScale(X_val, MIN, MAX)
y_val = MinMaxScale(y_val, MIN, MAX)
X_test = MinMaxScale(X_test, MIN, MAX)
y_test = MinMaxScale(y_test, MIN, MAX)
# 定义一个函数,用于将数据转换为张量
def make_Tensor(array):
return torch.from_numpy(array).float()
# 将训练集、验证集和测试集转换为张量
X_train = make_Tensor(X_train)
y_train = make_Tensor(y_train)
X_val = make_Tensor(X_val)
y_val = make_Tensor(y_val)
X_test = make_Tensor(X_test)
y_test = make_Tensor(y_test)
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Cell In[3], line 2
1 # 读取全球COVID-19确诊数据
----> 2 confirmed = pd.read_csv('time_series_covid19_confirmed_global.csv')
3 # 筛选出韩国的数据
4 confirmed[confirmed['Country/Region']=='Korea, South']
File D:\Program Files\Python39\lib\site-packages\pandas\io\parsers\readers.py:1026, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend)
1013 kwds_defaults = _refine_defaults_read(
1014 dialect,
1015 delimiter,
(...)
1022 dtype_backend=dtype_backend,
1023 )
1024 kwds.update(kwds_defaults)
-> 1026 return _read(filepath_or_buffer, kwds)
File D:\Program Files\Python39\lib\site-packages\pandas\io\parsers\readers.py:620, in _read(filepath_or_buffer, kwds)
617 _validate_names(kwds.get("names", None))
619 # Create the parser.
--> 620 parser = TextFileReader(filepath_or_buffer, **kwds)
622 if chunksize or iterator:
623 return parser
File D:\Program Files\Python39\lib\site-packages\pandas\io\parsers\readers.py:1620, in TextFileReader.__init__(self, f, engine, **kwds)
1617 self.options["has_index_names"] = kwds["has_index_names"]
1619 self.handles: IOHandles | None = None
-> 1620 self._engine = self._make_engine(f, self.engine)
File D:\Program Files\Python39\lib\site-packages\pandas\io\parsers\readers.py:1880, in TextFileReader._make_engine(self, f, engine)
1878 if "b" not in mode:
1879 mode += "b"
-> 1880 self.handles = get_handle(
1881 f,
1882 mode,
1883 encoding=self.options.get("encoding", None),
1884 compression=self.options.get("compression", None),
1885 memory_map=self.options.get("memory_map", False),
1886 is_text=is_text,
1887 errors=self.options.get("encoding_errors", "strict"),
1888 storage_options=self.options.get("storage_options", None),
1889 )
1890 assert self.handles is not None
1891 f = self.handles.handle
File D:\Program Files\Python39\lib\site-packages\pandas\io\common.py:873, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
868 elif isinstance(handle, str):
869 # Check whether the filename is to be opened in binary mode.
870 # Binary mode does not support 'encoding' and 'newline'.
871 if ioargs.encoding and "b" not in ioargs.mode:
872 # Encoding
--> 873 handle = open(
874 handle,
875 ioargs.mode,
876 encoding=ioargs.encoding,
877 errors=errors,
878 newline="",
879 )
880 else:
881 # Binary mode
882 handle = open(handle, ioargs.mode)
FileNotFoundError: [Errno 2] No such file or directory: 'time_series_covid19_confirmed_global.csv'
print(X_train.shape, X_val.shape, X_test.shape)
print(y_train.shape, y_val.shape, y_test.shape)
torch.Size([261, 5, 1]) torch.Size([33, 5, 1]) torch.Size([33, 5, 1])
torch.Size([261, 1]) torch.Size([33, 1]) torch.Size([33, 1])
4.3 LSTM 模型定义#
让我们创建一个 LSTM 模型。该类由CovidPredictor基本变量、初始化层的构造函数、初始化学习的函数reset_hidden_state和预测函数组成。forward
class CovidPredictor(nn.Module):
def __init__(self, n_features, n_hidden, seq_len, n_layers):
super(CovidPredictor, self).__init__()
self.n_hidden = n_hidden
self.seq_len = seq_len
self.n_layers = n_layers
self.lstm = nn.LSTM(
input_size=n_features,
hidden_size=n_hidden,
num_layers=n_layers
)
self.linear = nn.Linear(in_features=n_hidden, out_features=1)
def reset_hidden_state(self):
self.hidden = (
torch.zeros(self.n_layers, self.seq_len, self.n_hidden),
torch.zeros(self.n_layers, self.seq_len, self.n_hidden)
)
def forward(self, sequences):
lstm_out, self.hidden = self.lstm(
sequences.view(len(sequences), self.seq_len, -1),
self.hidden
)
last_time_step = lstm_out.view(self.seq_len, len(sequences), self.n_hidden)[-1]
y_pred = self.linear(last_time_step)
return y_pred
4.4 训练函数#
定义一个函数来学习第 4.3 节中定义的CovidPredictor类。train_model它接收训练数据和验证数据作为输入,并num_epochs表示要训练的时期数。表示每次都输出verboseepoch 。如果每个时期的验证损失值与之前的损失值进行比较并且不减少,则用于终止学习的因子。由于PyTorch保留了 ,因此每次输入新序列时,都必须对其进行初始化,以便不受前一个序列的影响。verbosepatiencepatiencepatiencehidden_statehidden_statehidden_state
def train_model(model, train_data, train_labels, val_data=None, val_labels=None, num_epochs=100, verbose = 10, patience = 10):
"""
训练一个基于LSTM的时间序列预测模型。
参数:
model (torch.nn.Module): 要训练的模型。
train_data (torch.Tensor): 训练数据。
train_labels (torch.Tensor): 训练标签。
val_data (torch.Tensor, 可选): 验证数据。默认为 None。
val_labels (torch.Tensor, 可选): 验证标签。默认为 None。
num_epochs (int, 可选): 训练的轮数。默认为 100。
verbose (int, 可选): 每隔多少轮打印一次训练信息。默认为 10。
patience (int, 可选): 早停机制的耐心值。默认为 10。
返回:
tuple: 包含训练后的模型、训练损失历史和验证损失历史的元组。
"""
# 定义损失函数为平均绝对误差(MAE)
loss_fn = torch.nn.L1Loss()
# 定义优化器为Adam
optimiser = torch.optim.Adam(model.parameters(), lr=0.001)
# 初始化训练损失历史列表
train_hist = []
# 初始化验证损失历史列表
val_hist = []
for t in range(num_epochs):
epoch_loss = 0
for idx, seq in enumerate(train_data):
# 重置模型的隐藏状态
model.reset_hidden_state()
# 在训练数据的维度上增加一个维度
seq = torch.unsqueeze(seq, 0)
# 使用模型进行预测
y_pred = model(seq)
# 计算预测值和真实值之间的损失
loss = loss_fn(y_pred[0].float(), train_labels[idx])
# 清空优化器的梯度
optimiser.zero_grad()
# 反向传播计算梯度
loss.backward()
# 更新模型的参数
optimiser.step()
epoch_loss += loss.item()
# 计算并记录每个epoch的平均训练损失
train_hist.append(epoch_loss / len(train_data))
if val_data is not None:
with torch.no_grad():
val_loss = 0
for val_idx, val_seq in enumerate(val_data):
# 重置模型的隐藏状态
model.reset_hidden_state()
# 在验证数据的维度上增加一个维度
val_seq = torch.unsqueeze(val_seq, 0)
# 使用模型进行预测
y_val_pred = model(val_seq)
# 计算预测值和真实值之间的损失
val_step_loss = loss_fn(y_val_pred[0].float(), val_labels[val_idx])
val_loss += val_step_loss
# 计算并记录每个epoch的平均验证损失
val_hist.append(val_loss / len(val_data))
## 每隔verbose轮打印一次训练和验证损失
if t % verbose == 0:
print(f'Epoch {t} train loss: {epoch_loss / len(train_data)} val loss: {val_loss / len(val_data)}')
## 每隔patience轮检查一次是否需要早停
if (t % patience == 0) & (t != 0):
## 如果验证损失开始增加,则触发早停
if val_hist[t - patience] < val_hist[t] :
print('\n Early Stopping')
break
elif t % verbose == 0:
# 如果没有验证数据,则只打印训练损失
print(f'Epoch {t} train loss: {epoch_loss / len(train_data)}')
return model, train_hist, val_hist
model = CovidPredictor(
n_features=1,
n_hidden=4,
seq_len=seq_length,
n_layers=1
)
model, train_hist, val_hist = train_model(
model,
X_train,
y_train,
X_val,
y_val,
num_epochs=100,
verbose=10,
patience=50
)
Epoch 0 train loss: 0.0846735675929835 val loss: 0.047220394015312195
Epoch 10 train loss: 0.03268902644807637 val loss: 0.03414301574230194
Epoch 20 train loss: 0.03255926527910762 val loss: 0.03243739902973175
Epoch 30 train loss: 0.032682761279652 val loss: 0.033064160495996475
Epoch 40 train loss: 0.0325928641549201 val loss: 0.032514143735170364
Epoch 50 train loss: 0.032316437919741904 val loss: 0.033000096678733826
Epoch 60 train loss: 0.03259847856704788 val loss: 0.03266565129160881
Epoch 70 train loss: 0.03220883647418827 val loss: 0.032897673547267914
Epoch 80 train loss: 0.03264666339685834 val loss: 0.032588861882686615
Epoch 90 train loss: 0.032349443449406844 val loss: 0.03221791982650757
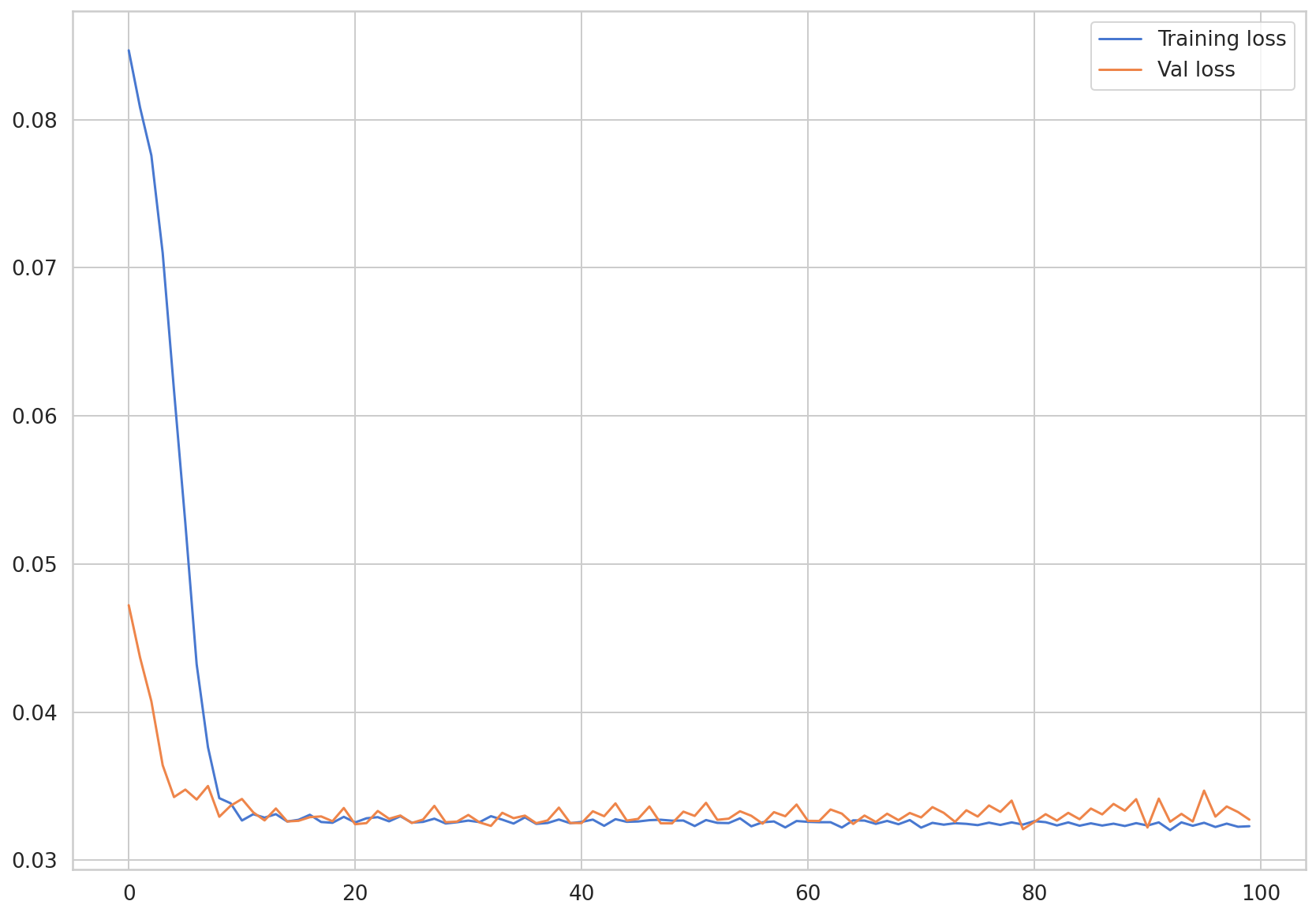
train_hist让我们可视化存储在和val_hist中的损失值。
plt.plot(train_hist, label="Training loss")
plt.plot(val_hist, label="Val loss")
plt.legend()
<matplotlib.legend.Legend at 0x7f76de333fd0>
4.5 预测#
在本节中,我们将利用构建好的模型对新输入的数据进行预测。当前构建的模型利用从t-5时刻到t-1时刻的数据来预测t时刻的确诊人数。同样地,如果输入实际观测到的从t-5到t-1的新数据,那么就能够对t时刻的确诊人数进行预测,这被称为“单步”(One-Step)预测。这是一种利用过去数据仅对前一个单位进行预测的方法。
而利用过去数据对两个单位、三个单位等多个单位之前进行预测的情况被称为“多步”(Multi-Step)预测。“多步”预测大致分为两种方法,即利用此前构建的进行“单步”预测的模型的方法以及利用“序列到序列”(seq2seq)结构模型的方法。
第一种方法是利用“单步”预测模型返回的t时刻的预测值\(\hat{t}\),以t-4、t-3、t-2、t-1、\(\hat{t}\)这些值来预测t+1时刻的值。像这样,可以将模型得出的预测值再次作为模型输入值反复进行预测,但会出现预测值的误差累积,从而导致预测性能逐渐下降的现象。
第二种方法是利用“序列到序列”(seq2seq)结构进行预测。这是一种按照想要预测的未来时间段来设置“解码器”(decoder)长度进行预测的方法。其优点是通过“解码器”网络,在计算预测值时能够利用附加信息,但预测的时间单位必须固定。
在本节中,我们将通过代码来确认利用“单步”预测模型反复进行“多步”预测的情况。
4.5.1 One-Step 预测#
One-Step首先,我们通过对之前创建的模型进行预测来检查模型性能。让我们对构建的测试数据进行预测。即使在进行预测时,每次输入新序列时,hidden_state都必须进行初始化,以便hidden_state不反映先前的序列。torch.unsqueeze使用函数增加输入数据的维度,使其具有模型预期的三维形状。然后,仅提取预测数据中存在的标量值并将preds其添加到列表中。
pred_dataset = X_test
with torch.no_grad():
preds = []
for _ in range(len(pred_dataset)):
model.reset_hidden_state()
y_test_pred = model(torch.unsqueeze(pred_dataset[_], 0))
pred = torch.flatten(y_test_pred).item()
preds.append(pred)
让我们将模型的预测值与实际值进行比较。y_test实际值存储在并且当前已缩放。要转换为原始比例,我们将使用以下公式。这是一个通过应用 MinMax 缩放时使用的公式转换为原始值的公式。
\(x = x_{scaled} * (x_{max} - x_{min}) + x_{min}\)
在本次数据中,\(x_{min}\)的值为0。因此,为了恢复到原始尺度,只需乘以\(x_{max}\)即可。
plt.plot(daily_cases.index[-len(y_test):], np.array(y_test) * MAX, label='True')
plt.plot(daily_cases.index[-len(preds):], np.array(preds) * MAX, label='Pred')
plt.xticks(rotation=45)
plt.legend()
<matplotlib.legend.Legend at 0x7f76dc9ac748>
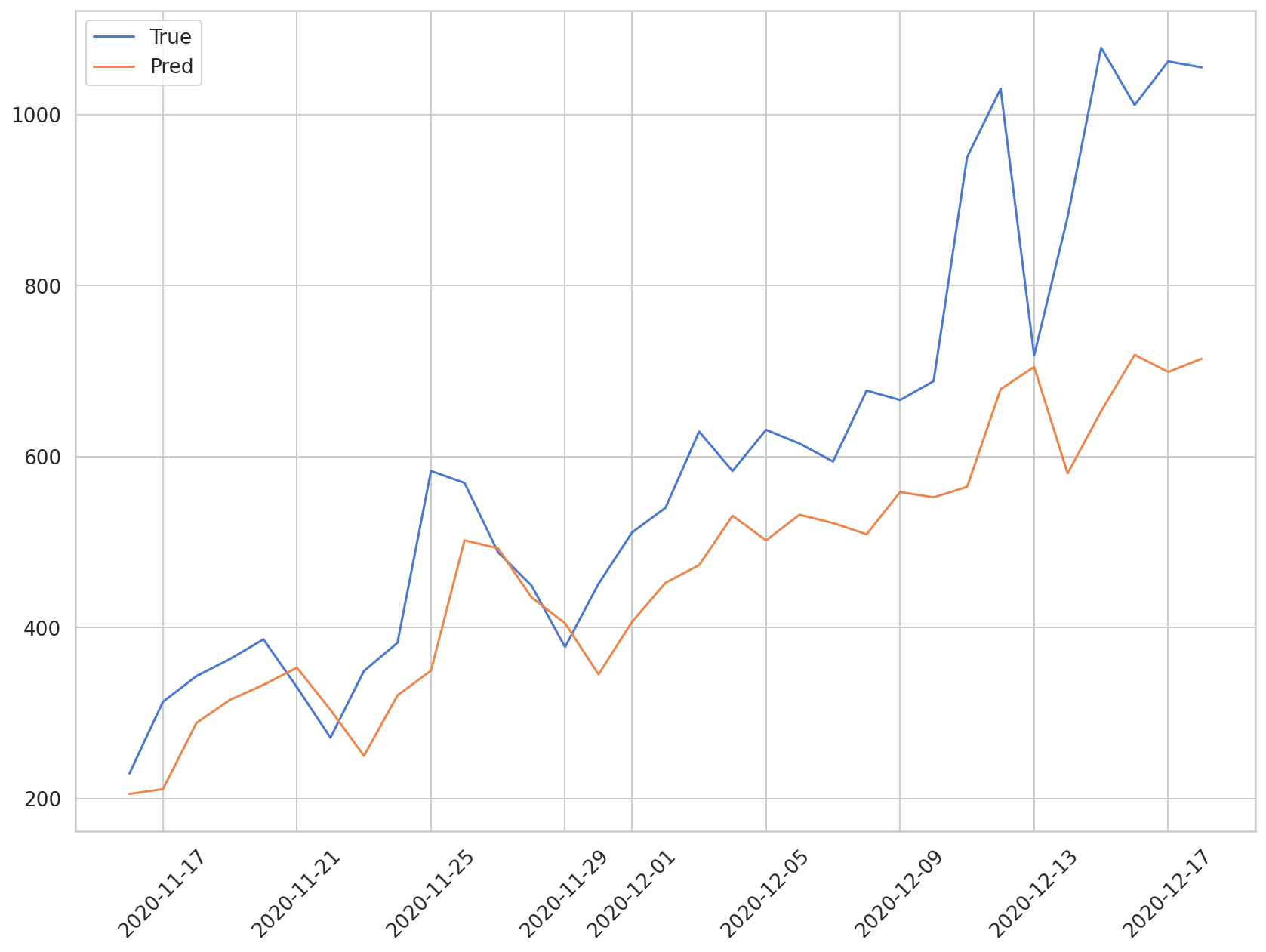
蓝色图代表测试数据的实际值,橙色图代表预测值。可以看到,该模型正在预测确诊病例呈上升趋势,但它不擅长预测确诊病例快速增加的区域。
让我们计算 MAE 值来找出预测值的平均误差。
def MAE(true, pred):
return np.mean(np.abs(true-pred))
MAE(np.array(y_test)*MAX, np.array(preds)*MAX)
247.3132225984521
可以看到测试数据的预测值与实际值平均相差250人左右。看来,如果不仅使用过去确诊病例的数量,而且还使用人口流动数据和人口统计数据,则可以进行更复杂的预测。
4.5.2 Multi-Step 多步预测#
One-StepMulti-Step我们通过重复使用预测模型来进行预测。我们将重复以下过程:将测试数据的第一个样本的预测值包含在输入序列中以预测下一个值,并将该值包含在输入序列中以预测下一个值。
def train_model(model, train_data, train_labels, val_data=None, val_labels=None, num_epochs=100, verbose = 10, patience = 10):
"""
训练一个基于LSTM的时间序列预测模型。
参数:
model (torch.nn.Module): 要训练的模型。
train_data (torch.Tensor): 训练数据。
train_labels (torch.Tensor): 训练标签。
val_data (torch.Tensor, 可选): 验证数据。默认为 None。
val_labels (torch.Tensor, 可选): 验证标签。默认为 None。
num_epochs (int, 可选): 训练的轮数。默认为 100。
verbose (int, 可选): 每隔多少轮打印一次训练信息。默认为 10。
patience (int, 可选): 早停机制的耐心值。默认为 10。
返回:
tuple: 包含训练后的模型、训练损失历史和验证损失历史的元组。
"""
# 定义损失函数为平均绝对误差(MAE)
loss_fn = torch.nn.L1Loss()
# 定义优化器为Adam
optimiser = torch.optim.Adam(model.parameters(), lr=0.001)
# 初始化训练损失历史列表
train_hist = []
# 初始化验证损失历史列表
val_hist = []
for t in range(num_epochs):
epoch_loss = 0
for idx, seq in enumerate(train_data):
# 重置模型的隐藏状态
model.reset_hidden_state()
# 在训练数据的维度上增加一个维度
seq = torch.unsqueeze(seq, 0)
# 使用模型进行预测
y_pred = model(seq)
# 计算预测值和真实值之间的损失
loss = loss_fn(y_pred[0].float(), train_labels[idx])
# 清空优化器的梯度
optimiser.zero_grad()
# 反向传播计算梯度
loss.backward()
# 更新模型的参数
optimiser.step()
epoch_loss += loss.item()
# 计算并记录每个epoch的平均训练损失
train_hist.append(epoch_loss / len(train_data))
if val_data is not None:
with torch.no_grad():
val_loss = 0
for val_idx, val_seq in enumerate(val_data):
# 重置模型的隐藏状态
model.reset_hidden_state()
# 在验证数据的维度上增加一个维度
val_seq = torch.unsqueeze(val_seq, 0)
# 使用模型进行预测
y_val_pred = model(val_seq)
# 计算预测值和真实值之间的损失
val_step_loss = loss_fn(y_val_pred[0].float(), val_labels[val_idx])
val_loss += val_step_loss
# 计算并记录每个epoch的平均验证损失
val_hist.append(val_loss / len(val_data))
## 每隔verbose轮打印一次训练和验证损失
if t % verbose == 0:
print(f'Epoch {t} train loss: {epoch_loss / len(train_data)} val loss: {val_loss / len(val_data)}')
## 每隔patience轮检查一次是否需要早停
if (t % patience == 0) & (t != 0):
## 如果验证损失开始增加,则触发早停
if val_hist[t - patience] < val_hist[t] :
print('\n Early Stopping')
break
elif t % verbose == 0:
# 如果没有验证数据,则只打印训练损失
print(f'Epoch {t} train loss: {epoch_loss / len(train_data)}')
return model, train_hist, val_hist
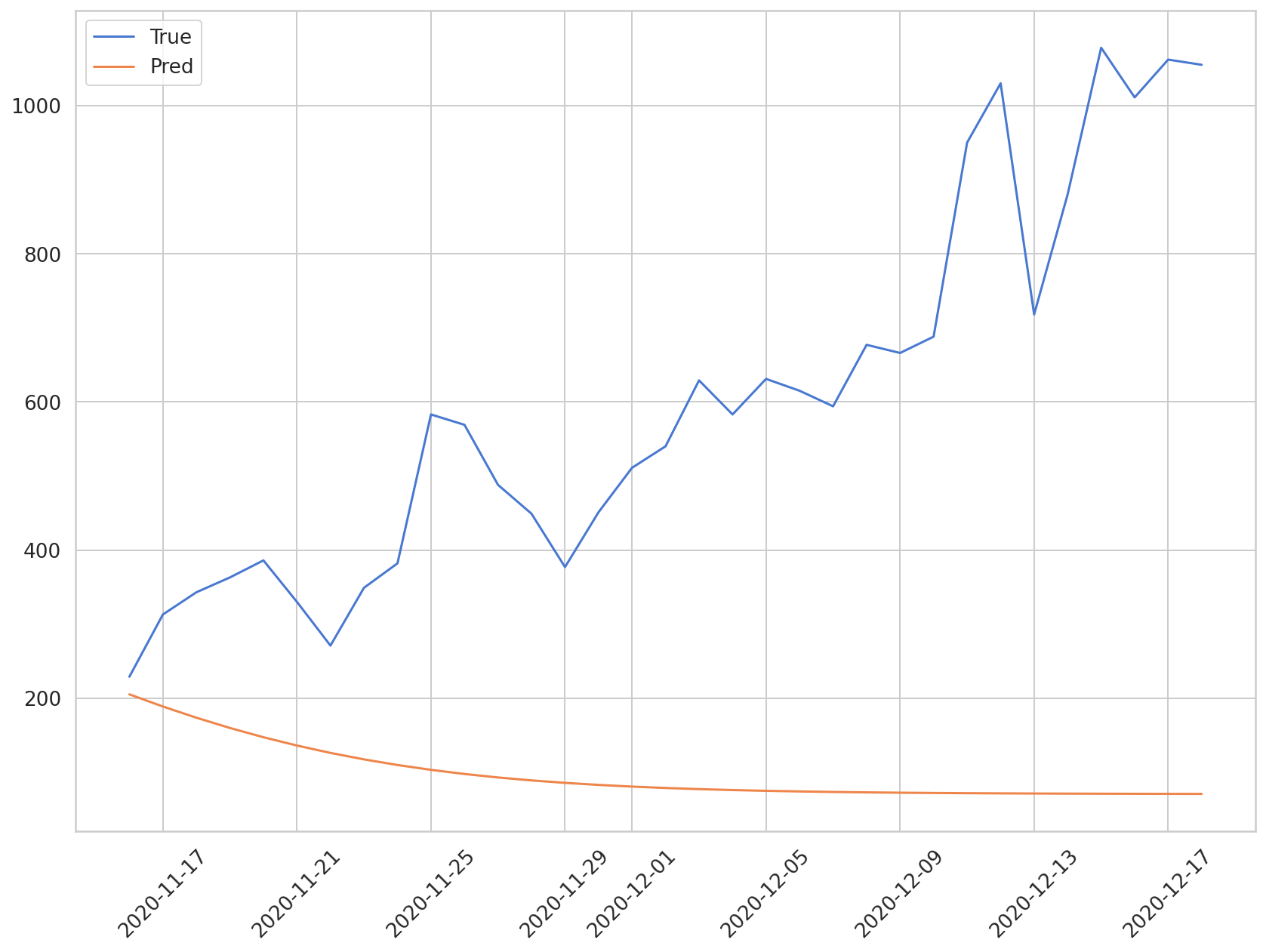
如前所述,随着预测周期的增加,该方法的误差会不断累积,导致模型性能难以保证。让我们在下图中可视化预测值与实际值的比较。
plt.plot(daily_cases.index[-len(y_test):], np.array(y_test) * MAX, label='True')
plt.plot(daily_cases.index[-len(preds):], np.array(preds) * MAX, label='Pred')
plt.xticks(rotation=45)
plt.legend()
<matplotlib.legend.Legend at 0x7f76dc271278>
到目前为止,我们一直在练习使用确诊的冠状病毒病例的数据构建 LSTM 模型。在下一章中,我们将进行一个练习,将 CNN-LSTM 应用于时间序列数据。