
5. CNN-LSTM#
![]()
在第 4 章中,我们使用 LSTM 来预测韩国确诊的 COVID-19 病例数。 LSTM由Hochreiter & Schmidhuber (1997)首次提出,此后随着研究的不断发展。
在本章中,我们将尝试不同的方法来提高模型性能。为了提高模型性能,有一些方法,例如更改批量大小和时期数、数据集整理、调整数据集比率、更改损失函数和更改模型,但在本练习中,我们将尝试通过更改来提高性能模型结构。让我们使用 CNN-LSTM 模型来看看它在预测韩国确诊的 COVID-19 病例数方面是否能表现更好。
首先,让我们加载本章所需的库。我们将使用最基本的torch、numpy以及pandas显示进程状态的tqdm可视化库。pylabmatplotlib
import torch
import os
import numpy as np
import pandas as pd
from tqdm import tqdm
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
from sklearn.preprocessing import MinMaxScaler
from pandas.plotting import register_matplotlib_converters
from torch import nn, optim
%matplotlib inline
%config InlineBackend.figure_format='retina'
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
rcParams['figure.figsize'] = 14, 10
register_matplotlib_converters()
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
<torch._C.Generator at 0x1f06e88b1f0>
5.1 数据集下载和预处理#
为了进行建模实践,我们将导入韩国累计确诊的冠状病毒数据。我们将使用 2.1 节中的代码。
!git clone https://github.com/Pseudo-Lab/Tutorial-Book-Utils
!python Tutorial-Book-Utils/PL_data_loader.py --data COVIDTimeSeries
!unzip -q COVIDTimeSeries.zip
'git' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
python: can't open file 'D:\3000-code\deeplearning\DeepLearning2023\Deeplearning\chapters\chpt4\Tutorial-Book-Utils\PL_data_loader.py': [Errno 2] No such file or directory
'unzip' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
pandas我们将使用该库加载新冠确诊患者数据,然后执行第 3 章中练习的数据预处理。数据集时段为2020年1月22日至2020年12月18日。
# 读取全球COVID-19确诊数据
confirmed = pd.read_csv('time_series_covid19_confirmed_global.csv')
# 筛选出韩国的数据
confirmed[confirmed['Country/Region']=='Korea, South']
# 提取韩国数据中从第4列开始的所有列,并转置
korea = confirmed[confirmed['Country/Region']=='Korea, South'].iloc[:,4:].T
# 将索引转换为日期格式
korea.index = pd.to_datetime(korea.index)
# 计算每日新增确诊病例数
daily_cases = korea.diff().fillna(korea.iloc[0]).astype('int')
def create_sequences(data, seq_length):
"""
创建时间序列数据。
参数:
data (pandas.DataFrame): 输入数据。
seq_length (int): 序列长度。
返回:
tuple: 包含输入序列和目标值的元组。
"""
xs = []
ys = []
for i in range(len(data)-seq_length):
# 取长度为seq_length的时间序列作为输入特征
x = data.iloc[i:(i+seq_length)]
# 取时间序列的下一个值作为目标值
y = data.iloc[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
# 设置序列长度为5
seq_length = 5
# 调用create_sequences函数生成时间序列数据
X, y = create_sequences(daily_cases, seq_length)
# 划分训练集、验证集和测试集
train_size = int(327 * 0.8)
X_train, y_train = X[:train_size], y[:train_size]
X_val, y_val = X[train_size:train_size+33], y[train_size:train_size+33]
X_test, y_test = X[train_size+33:], y[train_size+33:]
# 计算训练集的最小值和最大值
MIN = X_train.min()
MAX = X_train.max()
def MinMaxScale(array, min, max):
"""
对数据进行最小-最大归一化。
参数:
array (numpy.ndarray): 输入数据。
min (float): 最小值。
max (float): 最大值。
返回:
numpy.ndarray: 归一化后的数据。
"""
return (array - min) / (max - min)
# 对训练集、验证集和测试集进行归一化
X_train = MinMaxScale(X_train, MIN, MAX)
y_train = MinMaxScale(y_train, MIN, MAX)
X_val = MinMaxScale(X_val, MIN, MAX)
y_val = MinMaxScale(y_val, MIN, MAX)
X_test = MinMaxScale(X_test, MIN, MAX)
y_test = MinMaxScale(y_test, MIN, MAX)
# 定义一个函数,用于将数据转换为张量
def make_Tensor(array):
"""
将数据转换为张量。
参数:
array (numpy.ndarray): 输入数据。
返回:
torch.Tensor: 转换后的张量。
"""
return torch.from_numpy(array).float()
# 将训练集、验证集和测试集转换为张量
X_train = make_Tensor(X_train)
y_train = make_Tensor(y_train)
X_val = make_Tensor(X_val)
y_val = make_Tensor(y_val)
X_test = make_Tensor(X_test)
y_test = make_Tensor(y_test)
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Cell In[3], line 2
1 # 读取全球COVID-19确诊数据
----> 2 confirmed = pd.read_csv('time_series_covid19_confirmed_global.csv')
3 # 筛选出韩国的数据
4 confirmed[confirmed['Country/Region']=='Korea, South']
File D:\Program Files\Python39\lib\site-packages\pandas\io\parsers\readers.py:1026, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend)
1013 kwds_defaults = _refine_defaults_read(
1014 dialect,
1015 delimiter,
(...)
1022 dtype_backend=dtype_backend,
1023 )
1024 kwds.update(kwds_defaults)
-> 1026 return _read(filepath_or_buffer, kwds)
File D:\Program Files\Python39\lib\site-packages\pandas\io\parsers\readers.py:620, in _read(filepath_or_buffer, kwds)
617 _validate_names(kwds.get("names", None))
619 # Create the parser.
--> 620 parser = TextFileReader(filepath_or_buffer, **kwds)
622 if chunksize or iterator:
623 return parser
File D:\Program Files\Python39\lib\site-packages\pandas\io\parsers\readers.py:1620, in TextFileReader.__init__(self, f, engine, **kwds)
1617 self.options["has_index_names"] = kwds["has_index_names"]
1619 self.handles: IOHandles | None = None
-> 1620 self._engine = self._make_engine(f, self.engine)
File D:\Program Files\Python39\lib\site-packages\pandas\io\parsers\readers.py:1880, in TextFileReader._make_engine(self, f, engine)
1878 if "b" not in mode:
1879 mode += "b"
-> 1880 self.handles = get_handle(
1881 f,
1882 mode,
1883 encoding=self.options.get("encoding", None),
1884 compression=self.options.get("compression", None),
1885 memory_map=self.options.get("memory_map", False),
1886 is_text=is_text,
1887 errors=self.options.get("encoding_errors", "strict"),
1888 storage_options=self.options.get("storage_options", None),
1889 )
1890 assert self.handles is not None
1891 f = self.handles.handle
File D:\Program Files\Python39\lib\site-packages\pandas\io\common.py:873, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
868 elif isinstance(handle, str):
869 # Check whether the filename is to be opened in binary mode.
870 # Binary mode does not support 'encoding' and 'newline'.
871 if ioargs.encoding and "b" not in ioargs.mode:
872 # Encoding
--> 873 handle = open(
874 handle,
875 ioargs.mode,
876 encoding=ioargs.encoding,
877 errors=errors,
878 newline="",
879 )
880 else:
881 # Binary mode
882 handle = open(handle, ioargs.mode)
FileNotFoundError: [Errno 2] No such file or directory: 'time_series_covid19_confirmed_global.csv'
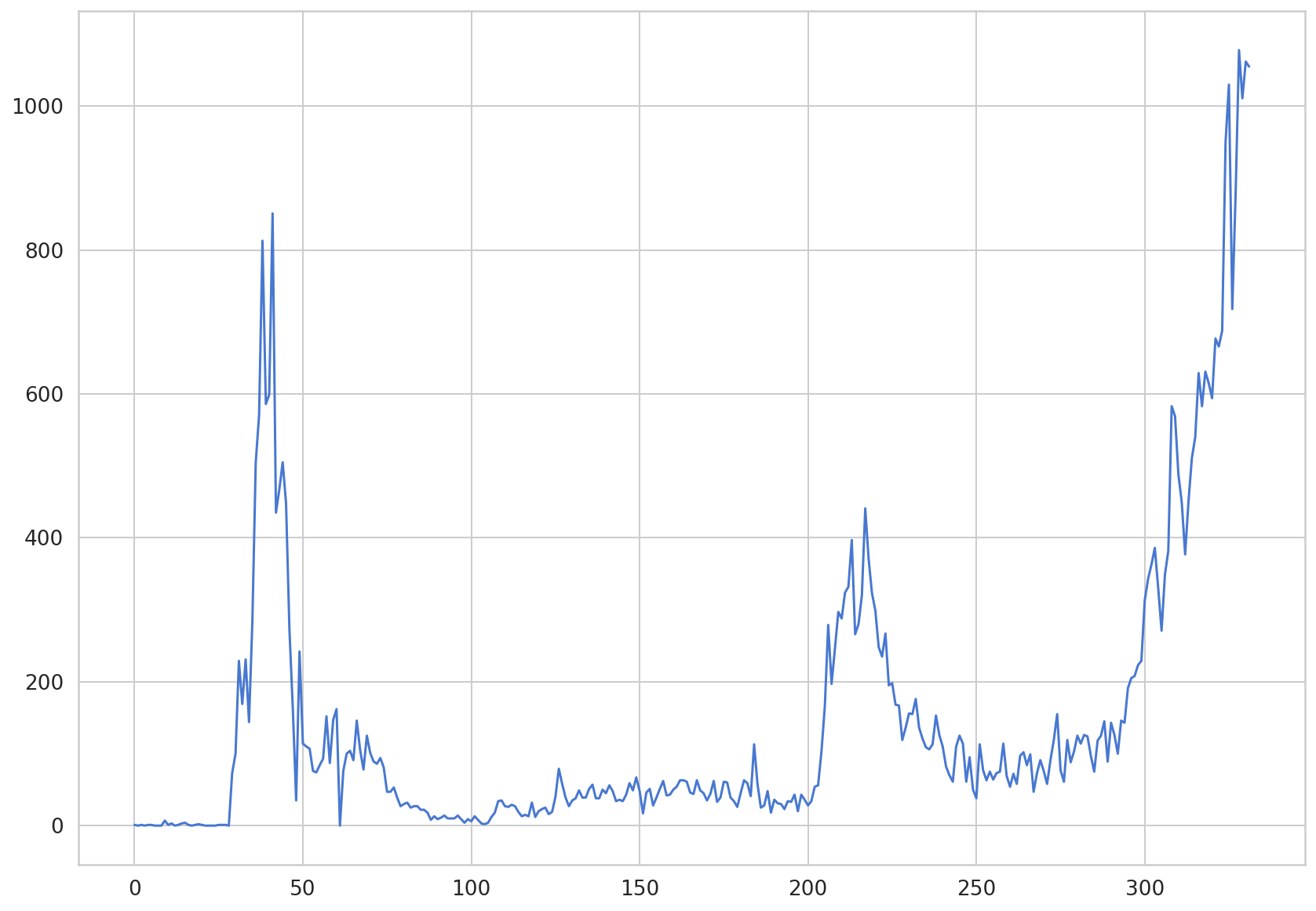
plt.plot(daily_cases.values)
[<matplotlib.lines.Line2D at 0x7f77cc4d1438>]
5.2 CNN-LSTM模型定义¶#
5.2.1 1D CNN(一维卷积神经网络)/Conv1D ¶#
第4章使用LSTM模型预测确诊病例数。在本章中,我们将通过向 LSTM 添加 CNN 层来进行预测。
CNN模型分为1D、2D和3D,一般的CNN是指通常用于图像分类的2D模型。这里,D是维度的缩写,根据输入数据类型使用1D、2D和3D CNN模型。
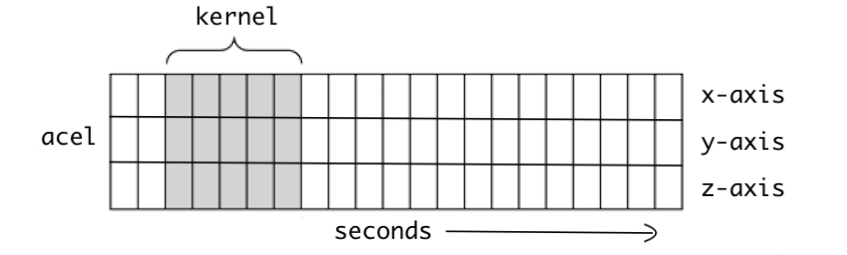
图 5-1 时间序列数据图(来源:理解 1D 和 3D 卷积神经网络 | Keras)
图 5-1 是一维 CNN 中内核运动的主要可视化。随着时间的推移,内核向右移动。一维 CNN 适用于处理时间序列数据。使用一维 CNN,可以提取变量之间的局部特征。
5.2.2 一维 CNN 测试#
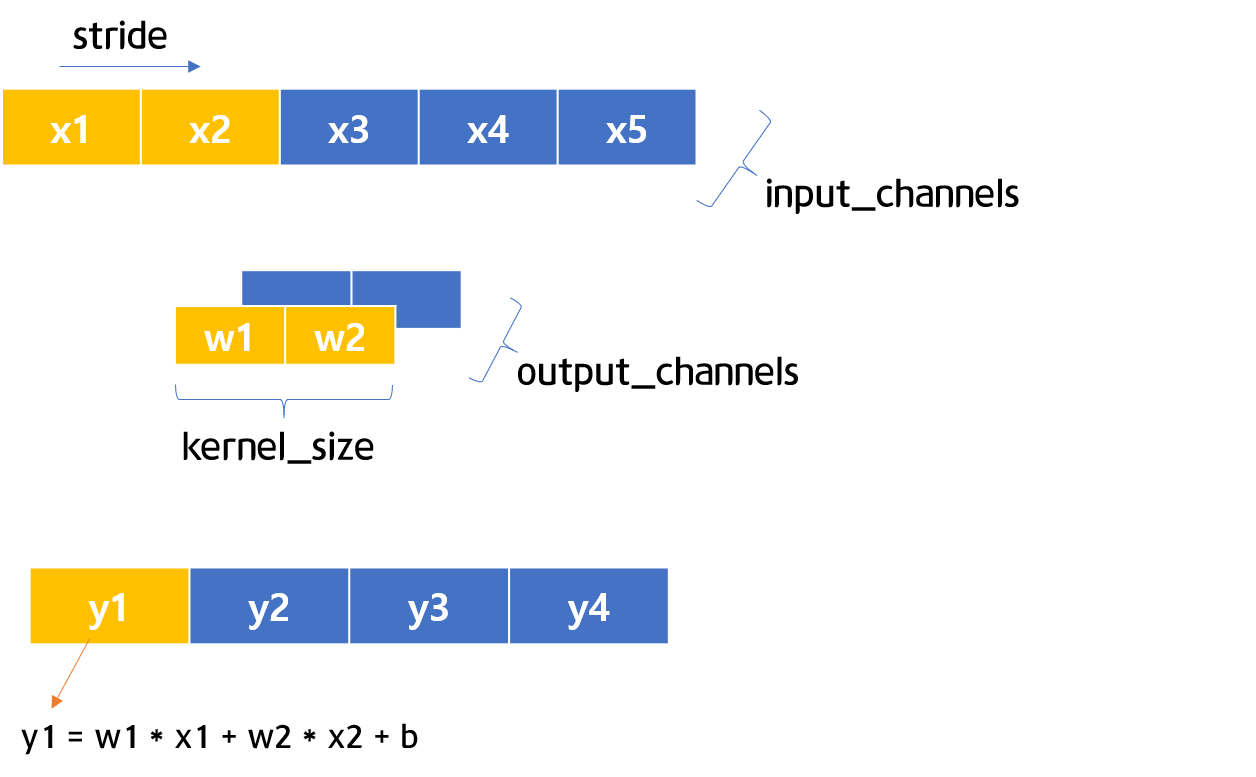
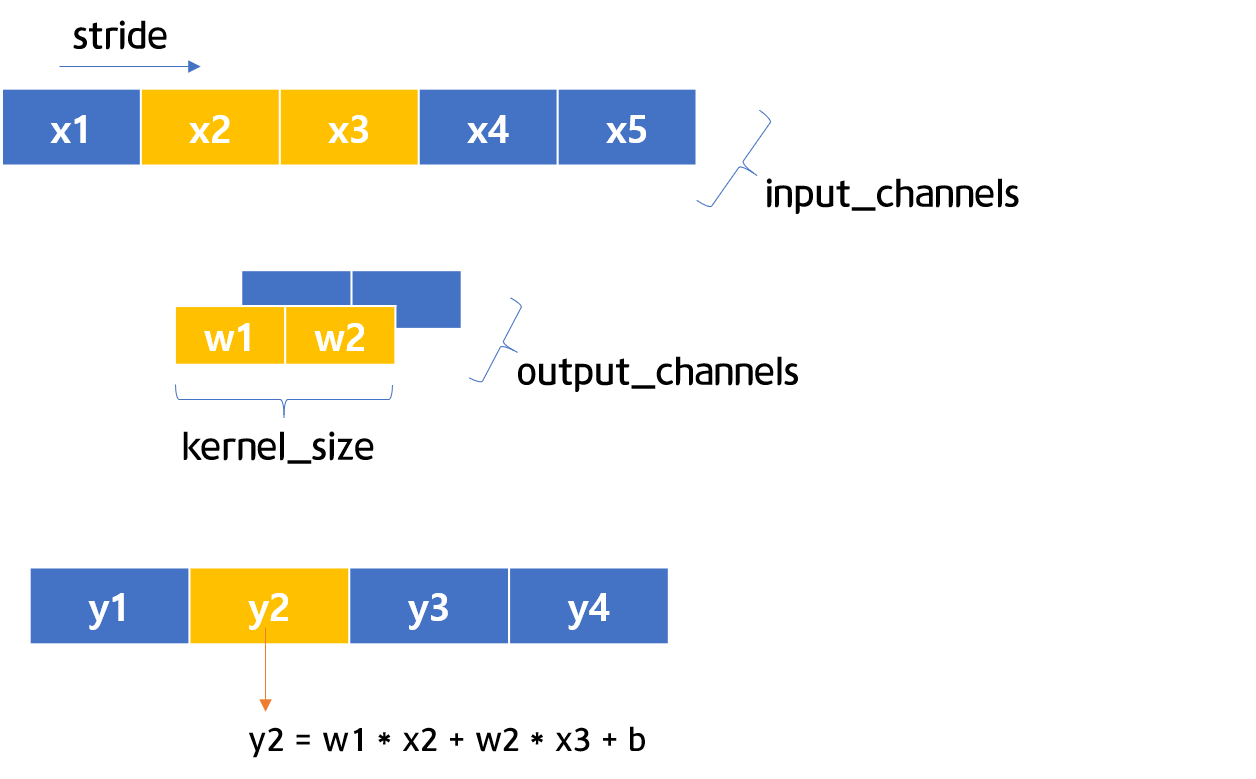
图 5-2 和 5-3 1D CNN 可视化
图 5-2 和 5-3 是一维 CNN 结构的可视化。如图5-2至图5-3所示,stride如果为1,则可以认为是一位一位移动。现在让我们通过简短的代码来了解一下 1D CNN。
首先,定义一维 CNN 层并将c其保存在 .如图5-2、5-3所示,1、1、2 in_channels、、均设置为1。然后,定义要用作输入值的变量并将其输入以计算预测值。out_channelskernel_sizestrideinputc
c = nn.Conv1d(in_channels=1, out_channels=1, kernel_size=2, stride=1)
input = torch.Tensor([[[1,2,3,4,5]]])
output = c(input)
output
tensor([[[-0.3875, -0.8842, -1.3808, -1.8774]]], grad_fn=<SqueezeBackward1>)
当5 个输入示例kernel_size通过 2 个 1D CNN 时,计算出 4 个值。让我们看看这些值是如何计算的。首先,c我们检查一下存储在 中的权重和偏差值。
for param in c.parameters():
print(param)
Parameter containing:
tensor([[[-0.1021, -0.3946]]], requires_grad=True)
Parameter containing:
tensor([0.5037], requires_grad=True)
第一个值代表权重值。kernel_size由于 是 2,所以总共有 2 个权重值。下一个值是偏置值。一个一维 CNN 层有一个偏置值。现在,让我们分别将值存储在变量w1、w2中。b
w_list = []
for param in c.parameters():
w_list.append(param)
w = w_list[0]
b = w_list[1]
w1 = w[0][0][0]
w2 = w[0][0][1]
print(w1)
print(w2)
print(b)
tensor(-0.1021, grad_fn=<SelectBackward>)
tensor(-0.3946, grad_fn=<SelectBackward>)
Parameter containing:
tensor([0.5037], requires_grad=True)
通过索引,权重值分别存储在变量w1、w2中。b在图5-2和5-3中y1 班级y2 您可以应用用于计算 的公式来output计算通过 1D CNN 时获得的值。 1D CNN滤波器经过3和4时的计算值如下。
w1 * 3 + w2 * 4 + b
tensor([-1.3808], grad_fn=<AddBackward0>)
可以看到这和output的第3个值是一样的,可以看到剩下的值也是这样计算的。
output
tensor([[[-0.3875, -0.8842, -1.3808, -1.8774]]], grad_fn=<SqueezeBackward1>)
5.3 CNN-LSTM 模型创建#
现在让我们创建一个 CNN-LSTM 模型。与第 4 章中创建的 LSTM 模型最大的区别是添加了 1D CNN 层。如果您查看下面的代码,您可以看到 1D CNN 层已添加CovidPredictor到该类中。nn.Conv1d
class CovidPredictor(nn.Module):
def __init__(self, n_features, n_hidden, seq_len, n_layers):
super(CovidPredictor, self).__init__()
self.n_hidden = n_hidden
self.seq_len = seq_len
self.n_layers = n_layers
self.c1 = nn.Conv1d(in_channels=1, out_channels=1, kernel_size = 2, stride = 1) # 1D CNN 레이어 추가
self.lstm = nn.LSTM(
input_size=n_features,
hidden_size=n_hidden,
num_layers=n_layers
)
self.linear = nn.Linear(in_features=n_hidden, out_features=1)
def reset_hidden_state(self):
self.hidden = (
torch.zeros(self.n_layers, self.seq_len-1, self.n_hidden),
torch.zeros(self.n_layers, self.seq_len-1, self.n_hidden)
)
def forward(self, sequences):
sequences = self.c1(sequences.view(len(sequences), 1, -1))
lstm_out, self.hidden = self.lstm(
sequences.view(len(sequences), self.seq_len-1, -1),
self.hidden
)
last_time_step = lstm_out.view(self.seq_len-1, len(sequences), self.n_hidden)[-1]
y_pred = self.linear(last_time_step)
return y_pred
5.4 模型训练#
让我们使用第 4 章中构建的train_model函数来学习模型。Adam被选为优化器。学习率0.001设置为 。被选为损失函数。MAE (Mean Absolute Error)
def train_model(model, train_data, train_labels, val_data=None, val_labels=None, num_epochs=100, verbose = 10, patience = 10):
loss_fn = torch.nn.L1Loss() #
optimiser = torch.optim.Adam(model.parameters(), lr=0.001)
train_hist = []
val_hist = []
for t in range(num_epochs):
epoch_loss = 0
for idx, seq in enumerate(train_data): # sample 별 hidden state reset을 해줘야 함
model.reset_hidden_state()
# train loss
seq = torch.unsqueeze(seq, 0)
y_pred = model(seq)
loss = loss_fn(y_pred[0].float(), train_labels[idx]) # 1개의 step에 대한 loss
# update weights
optimiser.zero_grad()
loss.backward()
optimiser.step()
epoch_loss += loss.item()
train_hist.append(epoch_loss / len(train_data))
if val_data is not None:
with torch.no_grad():
val_loss = 0
for val_idx, val_seq in enumerate(val_data):
model.reset_hidden_state() #seq 별로 hidden state 초기화
val_seq = torch.unsqueeze(val_seq, 0)
y_val_pred = model(val_seq)
val_step_loss = loss_fn(y_val_pred[0].float(), val_labels[val_idx])
val_loss += val_step_loss
val_hist.append(val_loss / len(val_data)) # val hist에 추가
## verbose loss
if t % verbose == 0:
print(f'Epoch {t} train loss: {epoch_loss / len(train_data)} val loss: {val_loss / len(val_data)}')
## patience early stopping
if (t % patience == 0) & (t != 0):
## loss early stop
if val_hist[t - patience] < val_hist[t] :
print('\n Early Stopping')
break
elif t % verbose == 0:
print(f'Epoch {t} train loss: {epoch_loss / len(train_data)}')
return model, train_hist, val_hist
model = CovidPredictor(
n_features=1,
n_hidden=4,
seq_len=seq_length,
n_layers=1
)
让我们快速浏览一下预测模型。
print(model)
CovidPredictor(
(c1): Conv1d(1, 1, kernel_size=(2,), stride=(1,))
(lstm): LSTM(1, 4)
(linear): Linear(in_features=4, out_features=1, bias=True)
)
现在让我们继续模型训练。
model, train_hist, val_hist = train_model(
model,
X_train,
y_train,
X_val,
y_val,
num_epochs=100,
verbose=10,
patience=50
)
Epoch 0 train loss: 0.08868540743530025 val loss: 0.04381682723760605
Epoch 10 train loss: 0.03551809817384857 val loss: 0.033296383917331696
Epoch 20 train loss: 0.033714159246412786 val loss: 0.033151865005493164
Epoch 30 train loss: 0.03314930358741047 val loss: 0.03351602330803871
Epoch 40 train loss: 0.03311298256454511 val loss: 0.03455767780542374
Epoch 50 train loss: 0.033384358255242594 val loss: 0.03596664220094681
Epoch 60 train loss: 0.03306851693218524 val loss: 0.035104189068078995
Epoch 70 train loss: 0.03264325369823853 val loss: 0.03546909987926483
Epoch 80 train loss: 0.03269847107237612 val loss: 0.035008616745471954
Epoch 90 train loss: 0.033151885962927306 val loss: 0.034998856484889984
我们通过可视化来看看训练损失和测试损失
plt.plot(train_hist, label="Training loss")
plt.plot(val_hist, label="Val loss")
plt.legend()
<matplotlib.legend.Legend at 0x7f77c2ac9fd0>
可以看到两个损失值收敛了。
5.5预测确诊病例数#
现在我们已经完成了模型的训练,让我们尝试预测确诊病例数。即使在进行预测时,每次输入新序列时,hidden_state都必须进行初始化,以便hidden_state不反映先前的序列。torch.unsqueeze使用函数增加输入数据的维度,使其具有模型预期的三维形状。然后,仅提取预测数据中存在的标量值并将preds其添加到列表中。
pred_dataset = X_test
with torch.no_grad():
preds = []
for _ in range(len(pred_dataset)):
model.reset_hidden_state()
y_test_pred = model(torch.unsqueeze(pred_dataset[_], 0))
pred = torch.flatten(y_test_pred).item()
preds.append(pred)
plt.plot(np.array(y_test)*MAX, label = 'True')
plt.plot(np.array(preds)*MAX, label = 'Pred')
plt.legend()
<matplotlib.legend.Legend at 0x7f77c29aafd0>
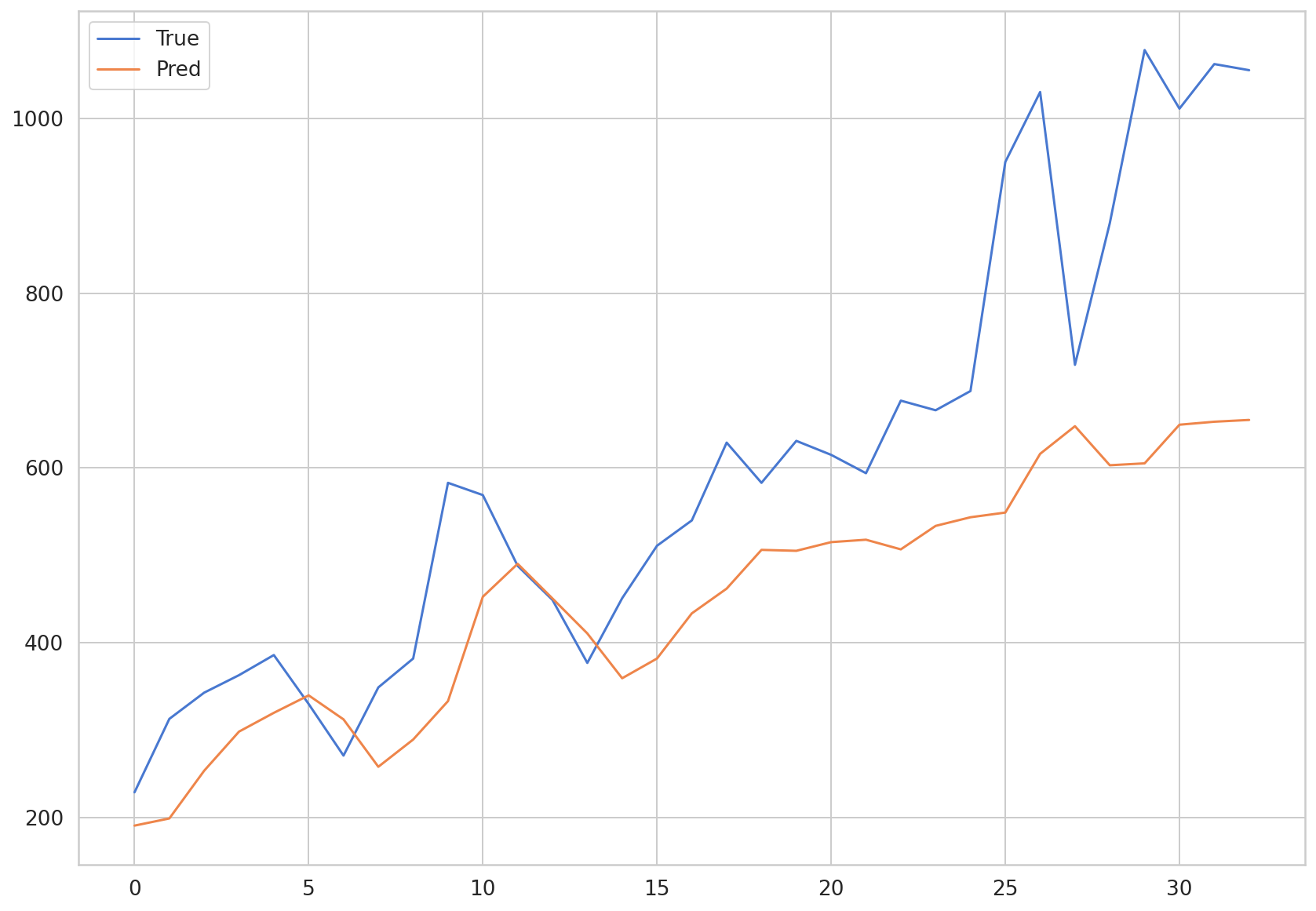
def MAE(true, pred):
return np.mean(np.abs(true-pred))
MAE(np.array(y_test)*MAX, np.array(preds)*MAX)
247.63305325632362
仅使用 LSTM 的模型的 MAE 也约为 250。您可以看到,新冠确诊患者数据的性能没有显着差异。这可以看作是因为 LSTM 和 CNN-LSTM 的损失都收敛到了特定值,也可以看作是因为输入数据与模型结构相比过于简单。
上面,我们练习使用韩国数据集和 CNN-LSTM 模型来预测确诊的 COVID-19 病例数量。通过本教程,我们从数据集探索和数据集预处理开始,学习了 LSTM 模型,进行了预测,甚至使用了 CNN-LSTM 模型。
确实,如果数据不多,时间序列预测的准确性就会降低。在本教程中,我们将仅使用确诊病例数数据来学习深度学习模型。此外,我们鼓励您使用各种数据集学习深度学习模型。